[Algorithm] 정렬 알고리즘
이것이 취업을 위한 코딩 테스트다 with 파이썬 (나동빈 저) 를 참고해 작성한 포스트입니다.
정렬은 데이터 집합을 특정한 기준 에 따라 순서대로 나열하는 작업입니다.
특정한 기준으로는 숫자의 내림차순과 오름차순, 문자열의 길이 혹은 각 문자의 합 등
사용자의 필요에 따라 여러 가지가 될 수 있습니다.
정렬 알고리즘은 알고리즘의 효율성을 표현하는데 자주 사용됩니다.
그 중에서도 제한 시간 안에 결과를 출력하기 위해 Big-O 표현을 사용합니다.
만약 C언어를 기준으로 1억회 연산하는 시간은 1초 라고 하였을 때,
데이터가 10,000개 인 집합을 1초안에 정렬하려고 하면
정렬 알고리즘의 시간복잡도가 \(O(N ^ 2)\) 이거나 더 빠른 알고리즘을 사용해야
제한 시간인 1초 안에 정렬을 완료할 수 있습니다.
이번 포스트에서는 여러 정렬 알고리즘 중 주로 사용되는 선택 정렬, 삽입 정렬 퀵 정렬, 계수 정렬 을
오름차순 으로 정렬하면서 소개하겠습니다.
선택 정렬
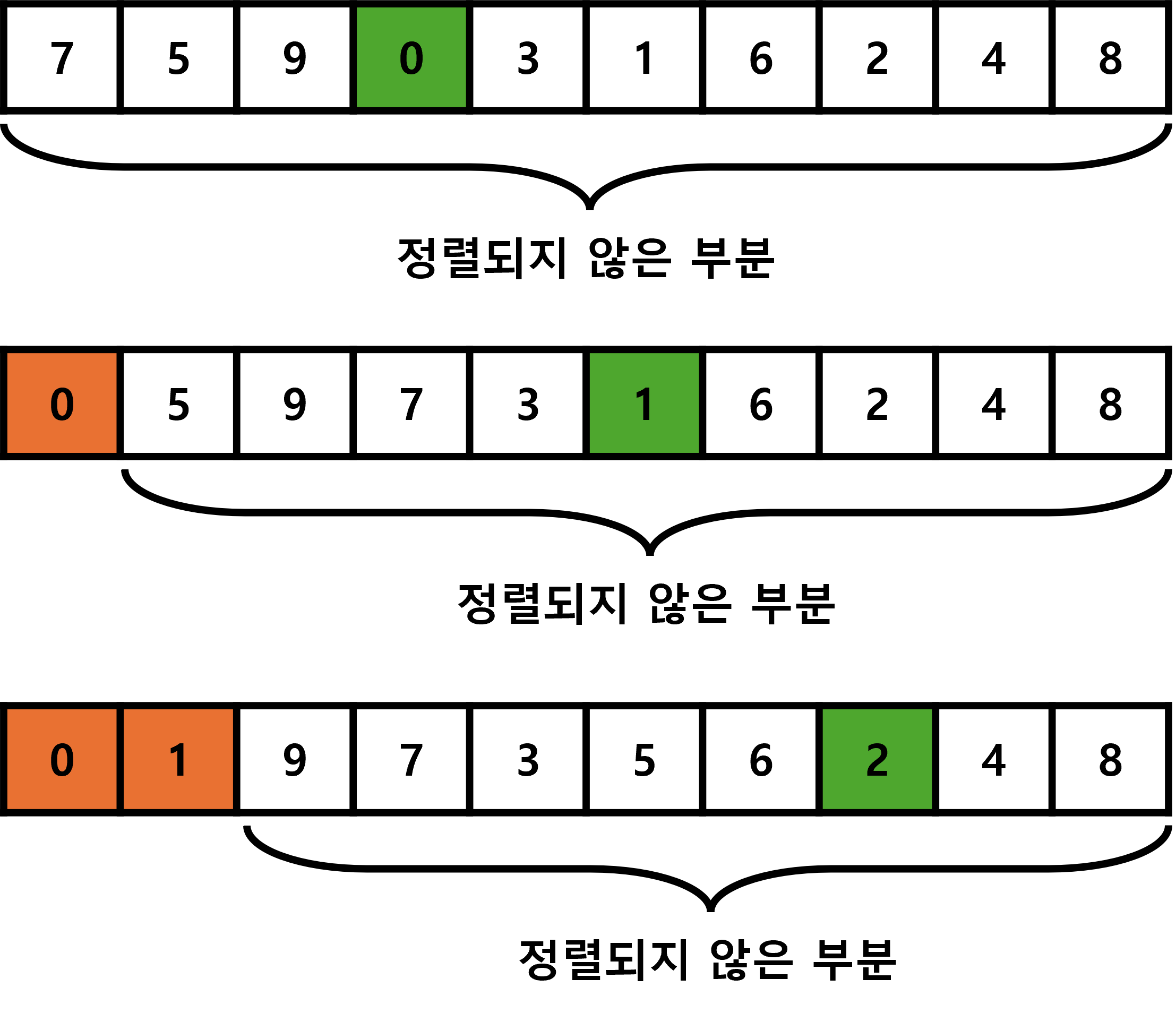
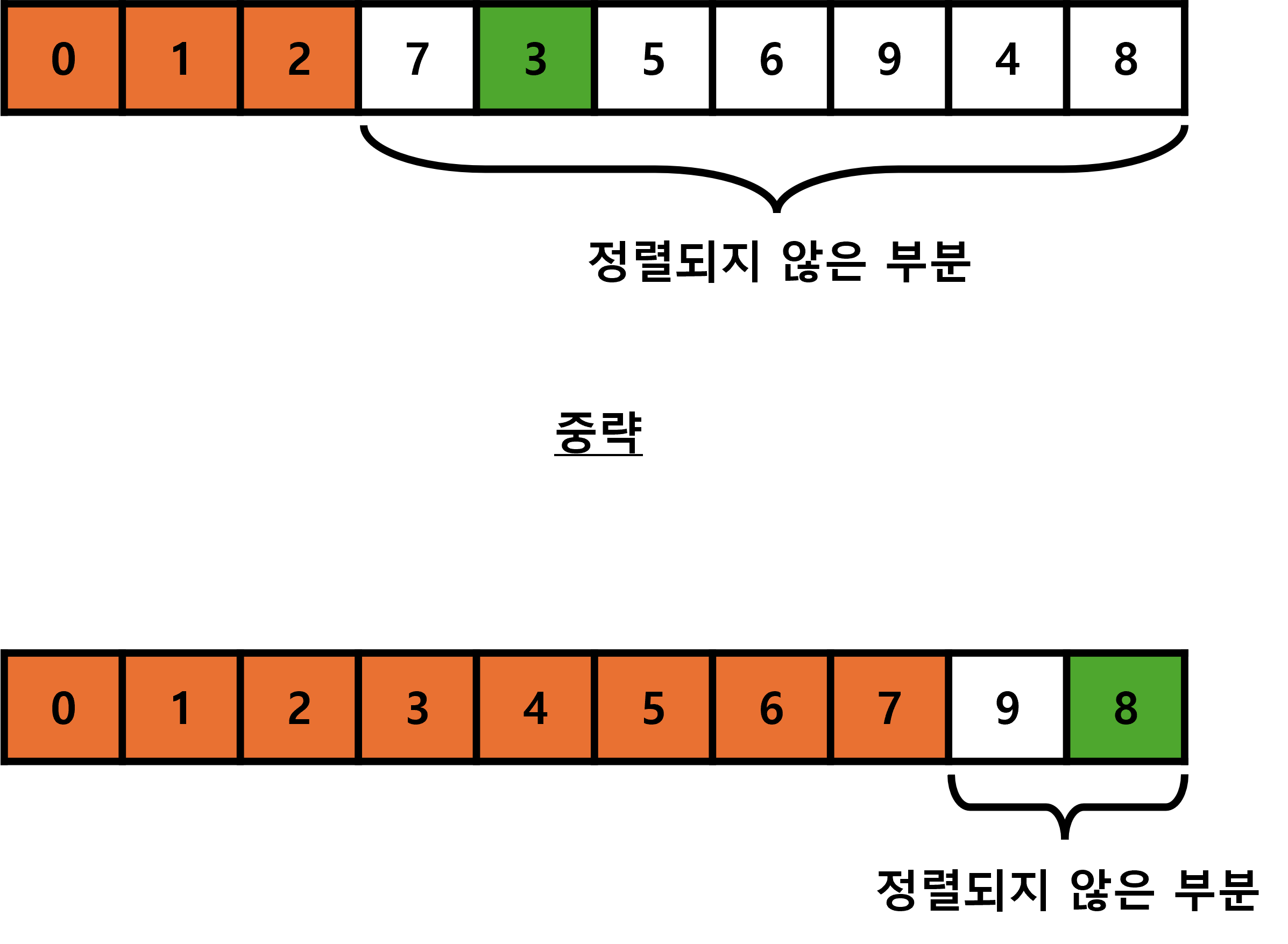
무작위로 입력되어 있는 데이터 집합에서 가장 작은 데이터를 찾아 정렬되지 않은 가장 앞 데이터와 교체합니다.
0부터 9까지 10개의 정수가 저장되어 있는 배열에서 선택 정렬을 실행할 때, 모습은 다음과 같습니다.
초록색 데이터가 정렬되지 않은 데이터 중 가장 작은 데이터이고 주황색은 정렬된 데이터 입니다.
C++ 코드로 선택 정렬을 구현하면 아래와 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
int arr[10]{7, 5, 9, 0, 3, 1, 6, 2, 4, 8};
for(int i = 0; i < 10; ++i)
{
int min_index = i;
for(int j = i + 1; j < 10; ++j)
{
if(arr[min_index] > arr[j])
{
min_index = j;
}
}
int temp = arr[i];
arr[i] = arr[min_index];
arr[min_index] = temp;
}
선택 정렬에서 최악의 연산 횟수는 비교할 때 마다 남은 데이터를 전부 비교하는 것 이므로 다음과 같습니다.
\(N + (N - 1) + (N - 2) + ... + 2 = \frac{N \times (N + 1)}{2}\)
이때, Big-O 규칙에 맞춰 최고차항만 남아서 다음과 같이 표현할 수 있습니다.
\[O(N ^ 2)\]삽입 정렬
데이터를 하나씩 확인하며, 각 데이터를 적절한 위치에 삽입하는 것이 삽입 정렬입니다.
선택 정렬과 비교하였을 때, 더 빠른 정렬이 가능하며 정렬이 거의 끝났거나, 정렬되어 있는
데이터에서는 퀵정렬 보다 빠른 정렬도 가능합니다.
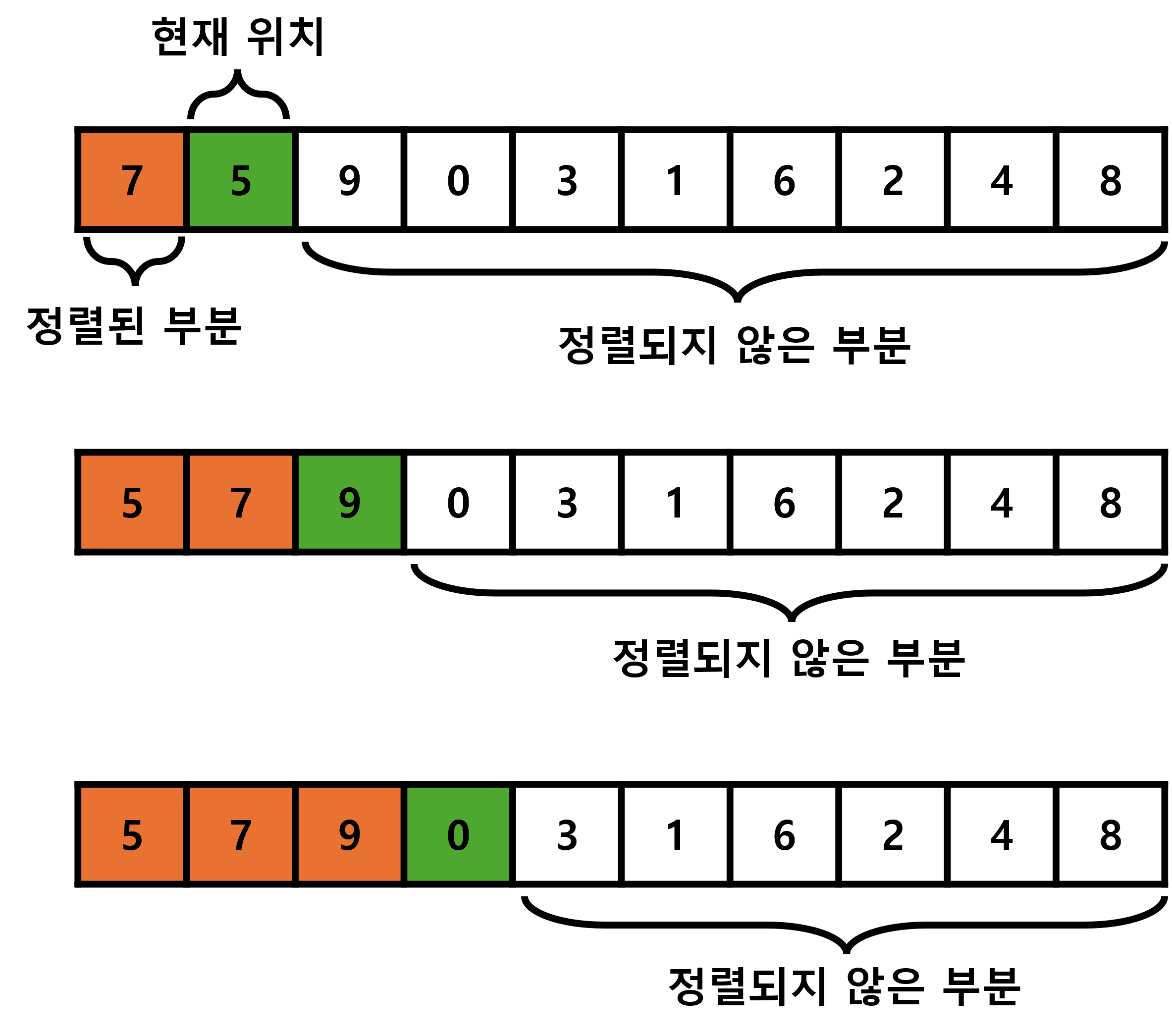
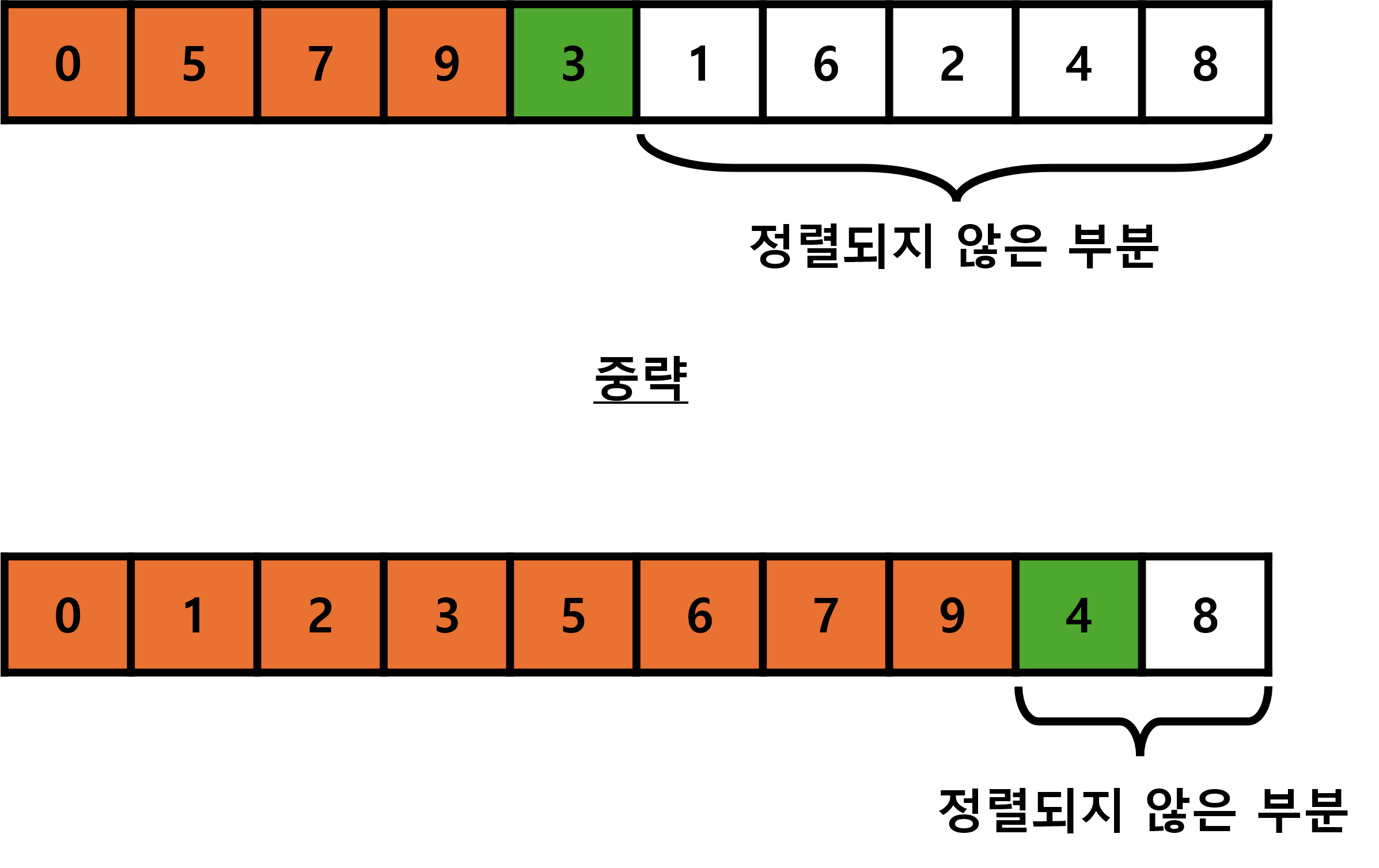
데이터에서 현재 선택된 데이터의 왼쪽 데이터는 이미 정렬이 완료되었다고 가정합니다.
따라서 아래 정렬 시작 상태에서 7은 정렬된 숫자라고 가정하고 두 번째 데이터인 5부터 정렬을 시작 합니다.
C++ 코드로 삽입 정렬을 구현하면 아래와 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
int arr[10]{7, 5, 9, 0, 3, 1, 6, 2, 4, 8};
for(int i = 0; i < 10; ++i)
{
for(int j = i; j > 0; --j)
{
if(arr[j] < arr[j - 1])
{
int temp = arr[j];
arr[j] = arr[j - 1];
arr[j - 1] = temp;
}
else
{
break;
}
}
}
삽입 정렬에서 최악의 연산 횟수는 새로운 데이터인 녹색 칸이 왼쪽의 정렬된 데이터인 주황색 칸에 입력될 때,
항상 최댓값으로 입력되어 비교 횟수가 주황색 칸의 개수만큼 있는 경우 입니다.
따라서 이를 수식으로 표현하면 다음과 같습니다.
\(2 + ... + (N - 2) + (N - 1) + N = \frac{N \times (N + 1)}{2}\)
위의 수식을 Big-O 규칙에 맞춰 정리하면 다음과 같습니다.
\[O(N ^ 2)\]그러나 데이터가 이미 정렬되어 있거나 거의 정렬이 완료된 상황에서는 \(O(N)\) 의 속도를 보여줍니다.
따라서 주어진 상황에 맞춰 어떤 정렬이 적합한지 판단해야 합니다.
퀵정렬
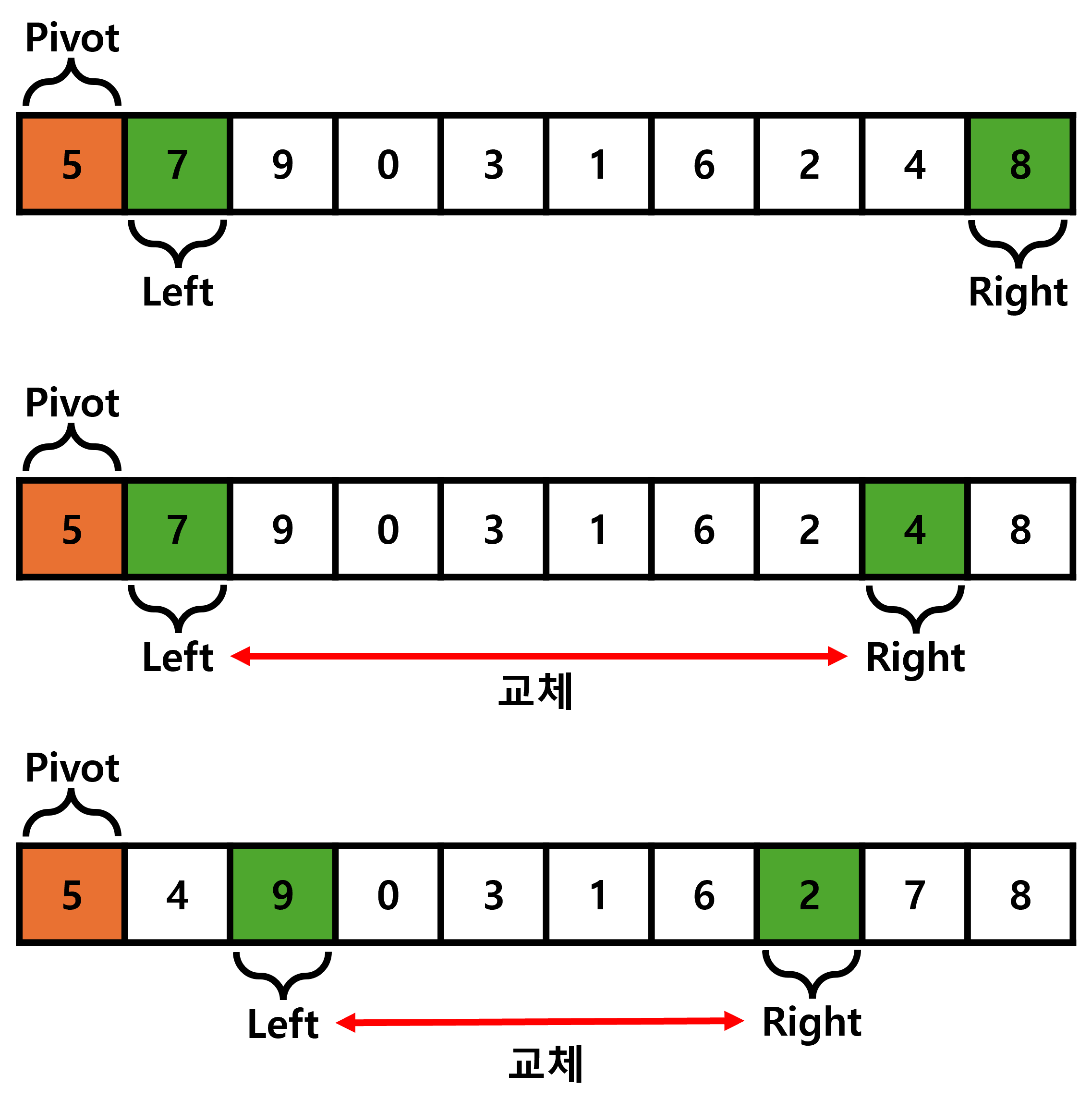
퀵 정렬은 Pivot 을 기준으로 데이터의 왼쪽 위치와 오른쪽 위치에서 서로를 향해 이동합니다.
이때 이동한 위치에서 각자 Pivot과 비교하였을 때,
왼쪽 값이 Pivot 보다 큰 경우, 오른쪽 값이 Pivot 보다 작은 경우 왼쪽 값과 오른쪽 값을 교환합니다.
왼쪽과 오른쪽이 각자 이동 중 만나면 Pivot을 기준으로 왼쪽과 오른쪽 부분을 위와 같은 과정으로 정렬시킵니다.
이때, 퀵 정렬의 핵심인 Pivot은 Hoare Partition 방식을 사용해 첫 번째 데이터를 Pivot으로 설정합니다.
C++ 코드로 퀵 정렬을 구현하면 아래와 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
vector<int> vec{7, 5, 9, 0, 3, 1, 6, 2, 4, 8};
void quick_sort(vector<int>& vec, int start, int end)
{
if(start >= end)
return;
int pivot = start;
int Left = start + 1;
int Right = end;
while(Left <= Right)
{
while(Left <= end && vec[Left] <= vec[pivot])
{
Left += 1;
}
while(Right > start && vec[Right] >= vec[pivot])
{
Right -= 1;
}
if(Left > Right)
{
int temp = vec[Right];
vec[Right] = vec[pivot];
vec[pivot] = temp;
}
else
{
int temp = vec[Right];
vec[Right] = vec[Left];
vec[Left] = temp;
}
}
quick_sort(vec, start, Right - 1);
quick_sort(vec, Right + 1, end);
}
quick_sort(vec, 0, (int)vec.size() - 1);
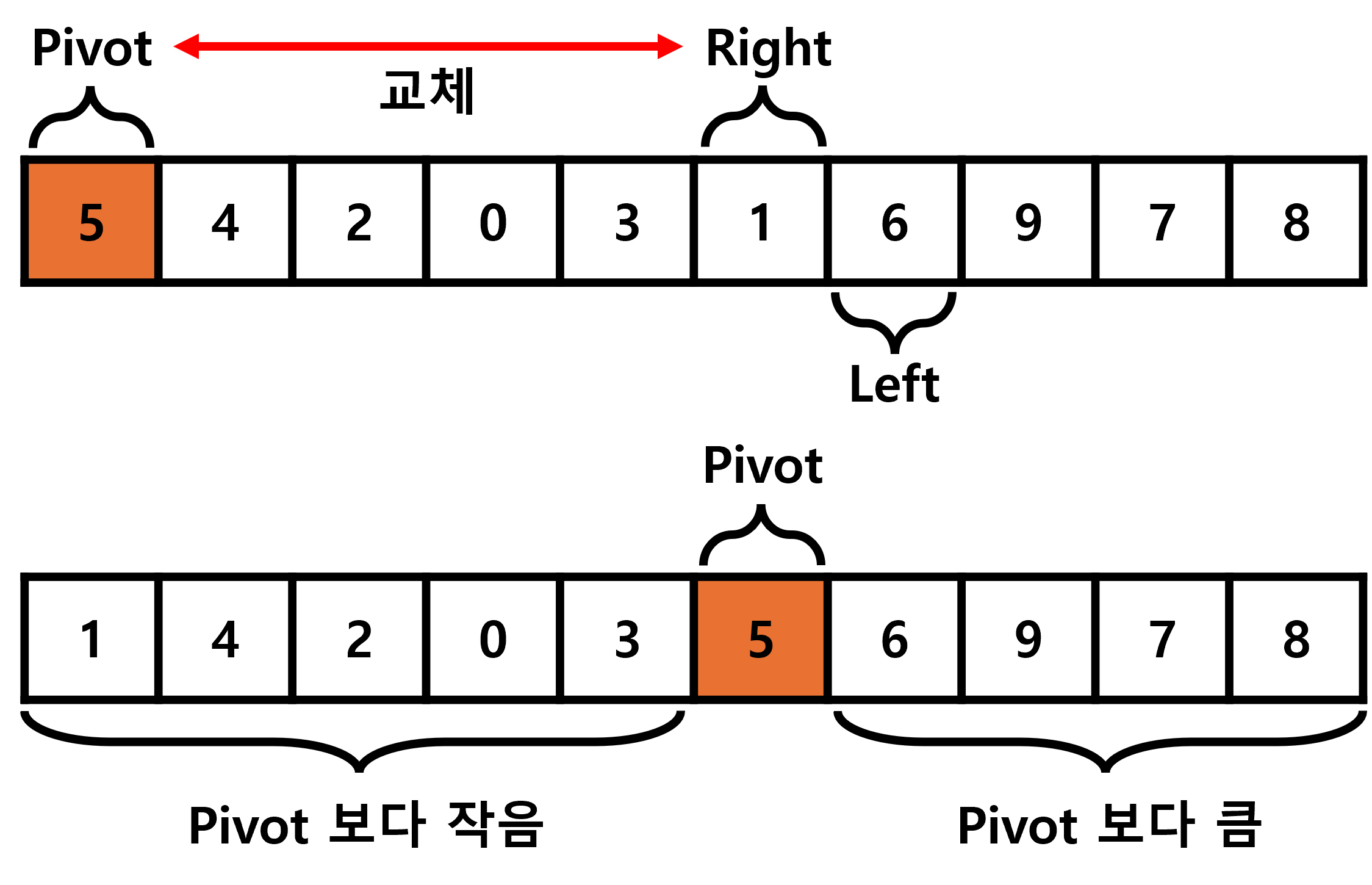
마지막 과정에서 Pivot 보다 작음, Pivot 보다 큼 부분을 각자 새롭게 동일한 방식으로 정렬합니다.
Left와 Right가 이동할 때는 각자 Pivot과 비교 하고
Left는 Pivot 보다 큰 값을 갖게 되었을 때, Right는 Pivot 보다 작은 값을 갖게 되었을 때까지 이동합니다.
때문에 위의 그림처럼 Left와 Right가 일정하게 함께 움직이지 않을 수 있습니다.
퀵 정렬은 무작위의 데이터 정렬에서는 평균으로 \(O(N \times log(N))\) 의 시간복잡도를 갖습니다.
그러나 이미 정렬되어 있는 데이터일 경우 시간 복잡도가 \(O(N ^ 2)\) 가 될 수 있습니다.
계수 정렬
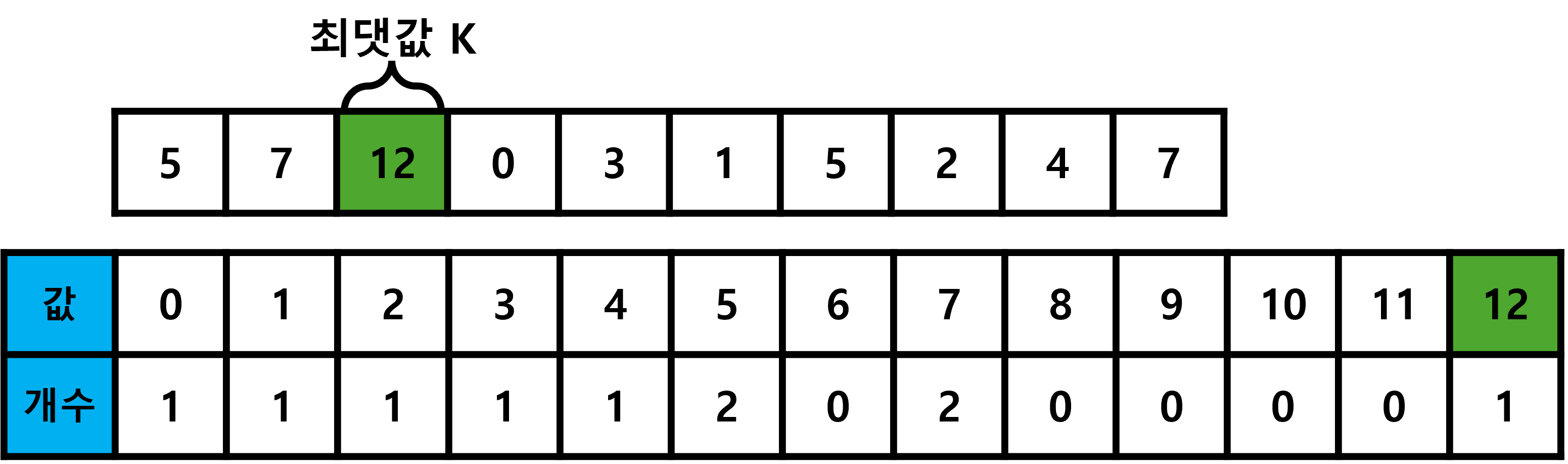
계수 정렬은 N개의 데이터 중 K가 최댓값일 때, 0부터 K까지의 숫자 개수를 기록할 컨테이너를 생성하고
전체 데이터를 순회하며 갯수 기록 컨테이너에 갯수를 기록합니다.
이후 정렬된 결과를 확인하기 위해서 K번 이동하며 0번 기록된 숫자를 제외하고 출력하면 됩니다.
C++ 코드로 계수 정렬을 구현하면 아래와 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
vector<int> vec{7, 5, 9, 0, 3, 1, 6, 2, 4, 8};
// algorithm header
int MAX = *max_element(vec.begin(), vec.end());
int* count = new int[MAX + 1]{ 0 };
for(int n : vec)
{
count[n] += 1;
}
for(int i = 0; i <= MAX; ++i)
{
for(int j = 0; j < count[i]; ++j)
{
cout << i << ' ';
}
}
계수 정렬은 위의 컨테이너처럼 사용하지 않는 공간이 있어
메모리 사용이 많을 수 있다는 단점이 있지만, 최댓값과 최소값의 차이가 작을 때,
시간 복잡도가 \(O(N + K)\) 라는 매우 빠른 정렬 속도를 보여줍니다.
출처
[이것이 취업을 위한 코딩 테스트다 with 파이썬 (나동빈 저)]